
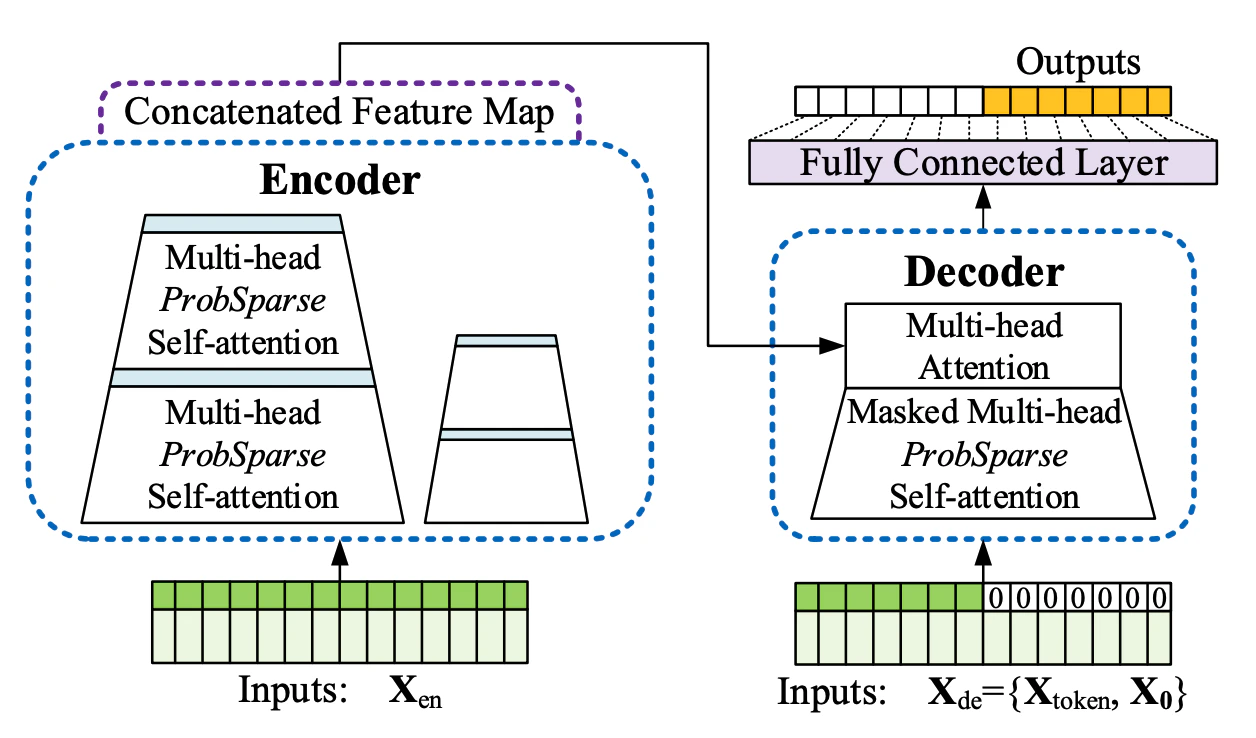
- A ProbSparse self-attention mechanism with an O time and memory complexity Llog(L). - A self-attention distilling process that prioritizes attention and efficiently handles long input sequences.
- An MLP multi-step decoder that predicts long time-series sequences in a single forward operation rather than step-by-step.
- It employs encoded autoregressive features obtained from a convolution network.
- It uses window-relative positional embeddings derived from harmonic functions.
- Absolute positional embeddings obtained from calendar features are utilized.
1. Informer
Informer
BaseModel
Informer
Informer.fit
fit method, optimizes the neural network’s weights using the
initialization parameters (learning_rate, windows_batch_size, …)
and the loss function as defined during the initialization.
Within fit we use a PyTorch Lightning Trainer that
inherits the initialization’s self.trainer_kwargs, to customize
its inputs, see PL’s trainer arguments.
The method is designed to be compatible with SKLearn-like classes
and in particular to be compatible with the StatsForecast library.
By default the model is not saving training checkpoints to protect
disk memory, to get them change enable_checkpointing=True in __init__.
Parameters:
Returns:
Informer.predict
Trainer execution of predict_step.
Parameters:
Returns:
Usage Example
2. Auxiliary Functions
ConvLayer
Module
ConvLayer
ProbAttention
Module
ProbAttention