
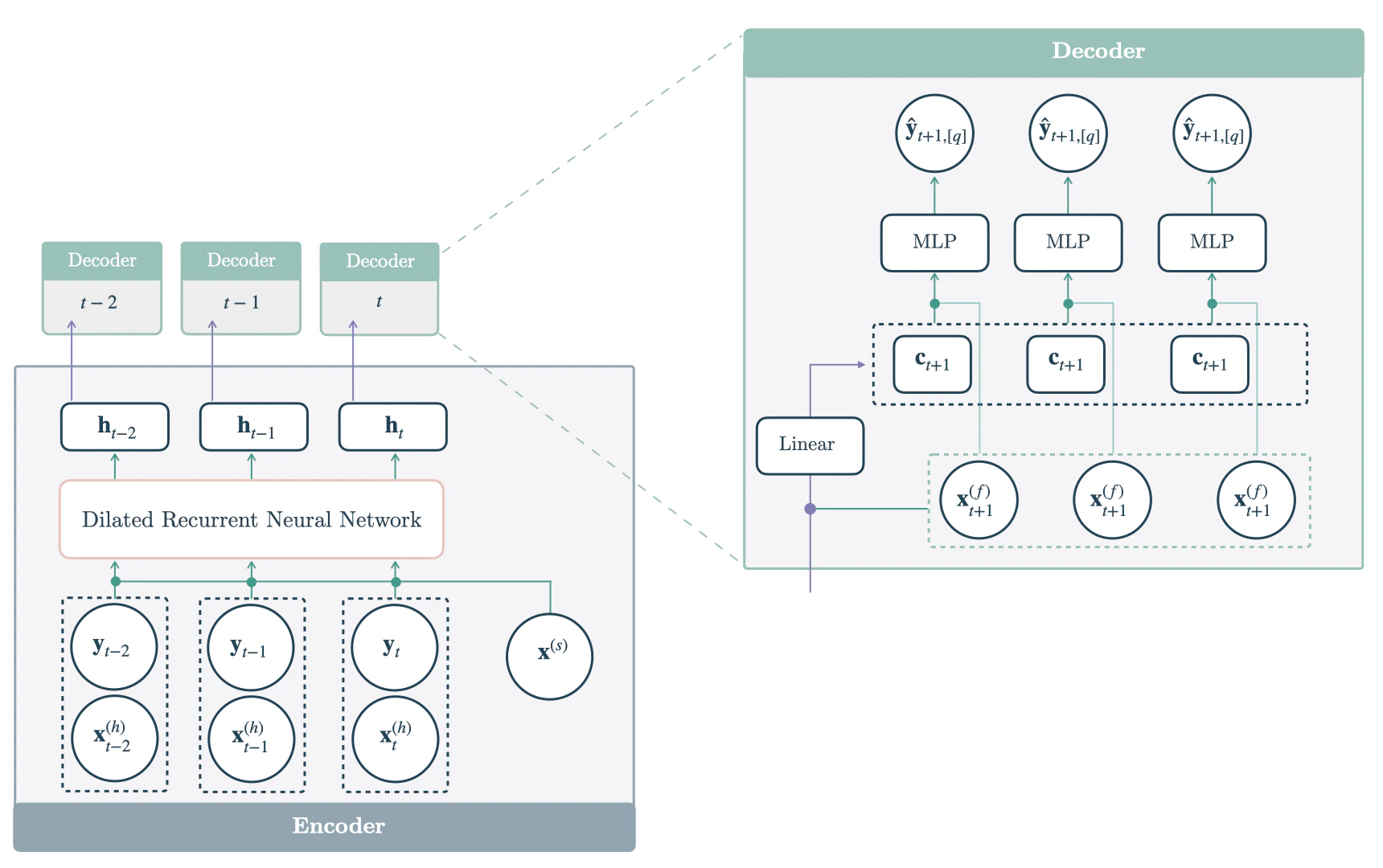
DilatedRNN)
addresses common challenges of modeling long sequences like vanishing
gradients, computational efficiency, and improved model flexibility to
model complex relationships while maintaining its parsimony. The
DilatedRNN
builds a deep stack of RNN layers using skip conditions on the temporal
and the network’s depth dimensions. The temporal dilated recurrent skip
connections offer the capability to focus on multi-resolution inputs.The
predictions are obtained by transforming the hidden states into contexts
, that are decoded and adapted into
through MLPs.
where , is the hidden state for time ,
is the input at time and is the
hidden state of the previous layer at , are
static exogenous inputs, historic exogenous,
are future exogenous available at the time
of the prediction.
References
- Shiyu Chang, et al. “Dilated Recurrent Neural Networks”.
- Yao Qin, et al. “A Dual-Stage Attention-Based recurrent neural network for time series prediction”.
- Kashif Rasul, et al. “Zalando Research: PyTorch Dilated Recurrent Neural Networks”.
Dilated RNN
DilatedRNN
BaseModel
DilatedRNN
Parameters:
DilatedRNN.fit
fit method, optimizes the neural network’s weights using the
initialization parameters (learning_rate, windows_batch_size, …)
and the loss function as defined during the initialization.
Within fit we use a PyTorch Lightning Trainer that
inherits the initialization’s self.trainer_kwargs, to customize
its inputs, see PL’s trainer arguments.
The method is designed to be compatible with SKLearn-like classes
and in particular to be compatible with the StatsForecast library.
By default the model is not saving training checkpoints to protect
disk memory, to get them change enable_checkpointing=True in __init__.
Parameters:
Returns:
DilatedRNN.predict
Trainer execution of predict_step.
Parameters:
Returns: